
근래에는 Modeler이자 SQLer로서의 연구를 주로 하고 있어서 R은 별로 사용하지 않는다.
큰 데이터를 주로 다루고, 통계적 분석보다는 개념적 연구들이기 때문에 SQL은 아주 강력한 도구로서 대부분의 요구사항을 충족시킨다.
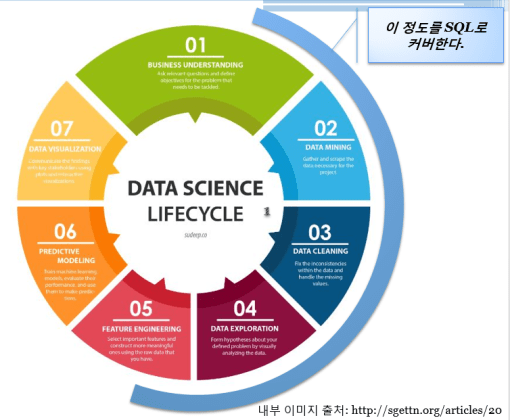
R이 보편적으로 다방면에 사용되고는 있지만, 사실 데이터 저장 – 전처리 – 분석의 과정을 SQL – R/SPSS/SAS 이런식으로 할수도 있고 Python – Python – R 이런 식으로 계획할 수도 있다.
또한 R의 강점이라는 visualization도 사실 고차원적인 통계적 분석을 할 것이 아니라면 SQL – Tableau /Spotfire로 꾸릴수도 있고 D3와 같은 선택도 가능하다.
결국 보편적으로 가장 먼저 ‘R을 쓰자’를 고려하기보다는 (R을 써보는게 연구목적인지… 여기서 R을 ML로 바꿔보면… ) 목적에 부합하는 기능들을 먼저 디자인하고 상황에 맞게 취사선택하면 되는 문제이다. (훌륭한 전문가들이 우리가 상상할 수 있는 기능들을 잘 수행하는 툴들을 쏟아내고있다. 컨트리뷰션에 항상 감사하자.)
이런 맥락에서 Data 어쩌구..가 막연히 하고 싶은 사람들이 “무엇부터 배울까요?” 하면 내가 생각하는 정답은 “기초통계부터”이다. 따라서 기초통계와 R을 같이 배우면 가장 좋다고 생각이 되지만 R을 통계 개념과는 독립적인 수행적 프로그램 언어로만 따로 떼서 가르치는 경우가 많아서 학생들이나 후배들에게 추천해주기가 참 난감하다.
현재로서는 R과 기초통계를 먼저 배우고, 그 과정에서 프로그램에 대한 접근을 한 번 해본 것을 토대로 Python으로 넘어가면 딱 좋을거라고 생각이 든다. 더불어, Data 어쩌구.. 가 아니라 Information 어쩌구.. Informatics를 하겠다는 사람이라면 SQL과 모델링, DB는 별도로 병행해서 커리큘럼을 짜주면 좋겠다는 생각을 가지고 있다.
이 글을 포함한 아주 구체적이고 소소한 포스팅은 “그럼 실제로 선생님은 어떻게 접근하세요?”에 대한 응답이기도 하다.
금번 연구 주제 중 하나가 web에서 data를 다운로드 받아다가 modeling을 하는 구조를 갖추고 있어서, (물론 web상의 contents에 대한 public licence는 확인하였다) 한땀한땀 excel을 받다가, 마침 R seminar 강의를 한 타임 하게 되어서 생각이 닿은 김에 R로 web scraping을 하기로 하였다.
전술했듯이, R로 구체적으로 내 자신의 프로젝트를 하는 경우는 별로 없었지만, 언제 무엇이 필요할지 모르고, 새로운 것을 배우는 것은 즐겁기 때문에? 왠지 모르게 통계특강이라면 자비로 가서 듣고 뿌듯~해하는걸 10년 넘게 즐겨온 나로서는 R에 대한 기본 지식은 갖추고 있었다는 점을 밝혀둔다.
간단한 구조는 다음과 같다.
MySQL (Target) –> R (URL의 excel을 data.frame으로 병합) –> MySQL(Result)
이런 아키텍쳐(간단해서 아키텍쳐라기 민망하지만)로 한 것은 단순히 Lab server에 대상 DB가 MySQL이 깔려있었고, web scraping이 R이 편리했기 때문이다.
- URL이 패턴을 가지고 있어서, DB에서 긁어올 대상 Target Name을 포함한 URL을 만들어 온다.
(MySQL을 사용했으므로 CONCAT()으로 다음과 같이 만든다.)
SELECT CONCAT(‘https://~…..’,Target Name,’_.xlsx’) FROM Target_Table
2. R에서 이 쿼리를 수행한다.
2.1. 그렇게 하기 위해서 DB connection을 만드는데, RODBC 패키지도 있지만 RMySQL 패키지를 사용한다. 단순히 경험상, 특정 DB이름을 지정한 패키지가 더 오류가 없을 수 있기 때문이다.
URL이 excel을 직접 열어서 저장하도록 연결할 것이기 때문에 readxl 패키지도 함께 설치.
install.packages(‘RMySQL’)
install.packages(‘readxl’)
설치했으면 불러와야 인지상정.
library(readxl)
library(RMySQL)
학생들에게도 늘 말하지만 컴퓨터는 백지라고 생각하면 좋다. 한땀한땀 가르쳐준다는 생각으로 하면 코드를 빼먹지 않는다.
2.2. DB 커넥션을 만들자.
dbConnect 함수의 argument로 넣을 dbDriver를 지정해주자.
drv = dbDriver(“MySQL”)
그리고 연결 생성
con <- dbConnect(drv, dbname=”default로 붙을 데이터베이스명칭”, host = ‘X.X.X.X’ , port = 3306, user = “mysql user name”, pwd = “mysql user name에 맞는 password”)
port 는 DB에서 확인하면 되는데, mySQL은 default가 3306이다.
(참고로 MSSQL은 1433, PostgreSQL은 5432 이다.)
2.3. 1.에서 만든 URL을 받아오자.
URL_List <- dbGetQuery(con, “SELECT CONCAT(‘https://~…..’,Target Name,’_.xlsx’) FROM Target_Table”)
그리고 예쁘게 for문을 돌면서 ULR에서 받아온 excel을 저장하고, data.frame에 적재한다.
( 처음 한 번 저장하는 예시 코드 )
url <- URL_List[[1]][1]
plf <- tempfile()
download.file(url.plf,mode=”wb”)
result <- read_excel(path = plf)
3. 읽어와서 수합한 데이터를 다시 DB에 저장한다.
dbWriteTable(con, “Table이름을 지정”, result, append=TRUE)
잘 저장이 되었으면 TRUE를 반환한다.
이제 데이터 정제 작업을 해야 하는데, 이 부분은 *개인적으로* SQL이 더 편하기 때문에 SQL로..
여기까지 코드 래핑하는데 반나절 정도 걸렸다.
한땀한땀 데이터를 확인하면서 저장하는 것을 선호하는 나이지만 (눈으로 많이 봐야 패턴 잡기가 좋고 중간단계 원본을 file로 저장해서 가지고 있는 것을 선호한다) 메인 화면으로부터 2depth를 들어가야 접근 가능한 URL을 메인 페이지에 있는 50여개의 목록으로부터 들어가서 excel을 받아 local에 저장하고 이 작업을 2가지 target에 대해서 진행 했어야 했는데, 의외로 가장 큰 퍼포먼스 복병은 excel file을 100번 “여는” 것이었다.
R을 이용한 scraping은 처음이라 퍼포먼스가 더 안좋을까봐 살짝 걱정도 하였는데 결과적으로 마음에 들어서, data modification이 main인 복잡한 다음 작업도 내일 R을 활용해서 코딩을 해 보기로 하였다. 물론 modeling은 DB로 넘어가서 할 예정이지만, DB에 넘길 수 있는 데이터 구조까지는 R에서 변환할 생각이다.
*Data 어쩌구.. 라는 표현은 Data scientist나 유사한 표현들을 비하하려는 목적이 아니라, 그 단어들의 적용이 너무 일상화되어(=오글거려서) 뜻이 오히려 흐려졌다고 생각해서 나온 표현이다.
*Information 어쩌구.. 라는 표현 역시 Informatician, Informaticist 등의 논란이 떠올라서 대략 이쯤..이라는 뜻으로 사용하였다.
